
Teadusuuringute aluseks olevad andmed soodustavad teadusliku mõistmise edusamme. Need andmekogumid sisaldavad olulisi vihjeid paljudele kõige pakilisematele küsimustele, millega teadlased praegu silmitsi seisavad, ja võivad heita uut valgust varasematele leidudele – kas kinnitada või muuta kehtetuks olemasolevad teaduslikud andmed ning avada võimalused uuteks uuringuteks ja arusaamadeks. Seda tüüpi teave kaob aga sageli teaduslike leidude avaldamise käigus, kuna andmeid ei jagata või neid ei tehta kättesaadavaks vormingus, millele on lihtne juurde pääseda ja mida on võimalik üle kuulata.
„Teaduses avaldatakse palju suurepäraseid töid PDF-dokumentidena. Võimalus artiklit printida ja lugeda on inimestele suurepärane, kuid suur osa PDF-failis esitatava koostamiseks kasutatud teabest jääb lõpuks peidetuks. Kui tahame saada suuremat pilti ja vaadata kõiki katseid, mis on tehtud ja mida on kirjanduses kirjeldatud teatud protsessi või reaktsiooni kohta, on meil väga raske kogu seda teavet kõigist nendest PDF-idest välja võtta. ,” selgitab ettevõtte tegevdirektor Simon Hodson ISC-CODATA.
Keemik Peter Murray-Rusti sõnade kohaselt võib PDF-failidest kasuliku teabe hankimine olla nagu "lehma rekonstrueerimine veiselihaburgerist".
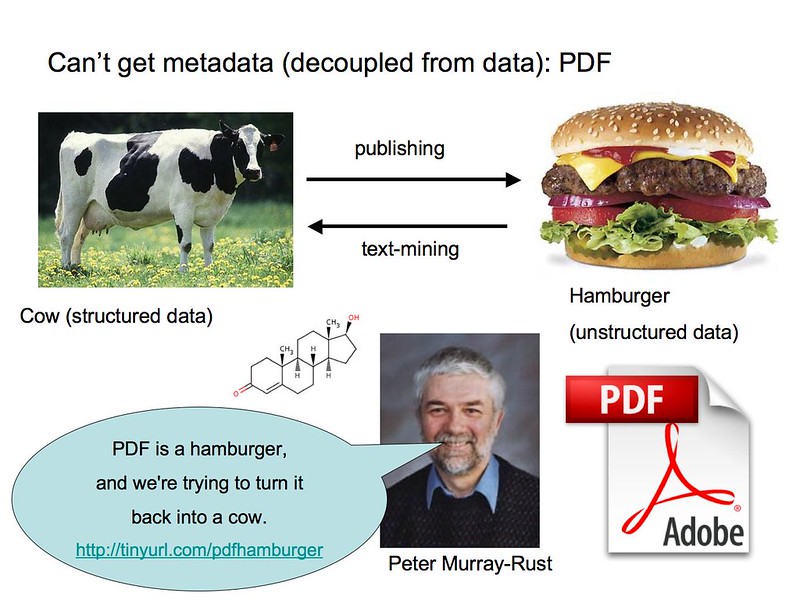
Paljude aastate pikkuse uurimistöö käigus on kogutud palju teaduslikke andmeid, kuid paljudel juhtudel pole see võimalik - ja kindlasti mitte kerge - leida need andmed ja teha päringuid, et võrrelda neid teiste leidude või käimasoleva tööga. Selle mõistatusega silmitsi seistes ja kooskõlas avatud teaduse nõudega töötavad teadlased praegu selle nimel, et võimaldada andmepõhist teadust raamistike kaudu, mis toetavad andmete juurdepääsetavust ja koostalitlusvõimet.
Üks uusimaid ja silmapaistvamaid lähenemisviise selle tegemiseks on FAIR, mis koondab endasse, millised andmed peavad olema, et need oleksid võimalikult kasutatavad ja väärtuslikud: FAIRi andmed on andmed, mis on Fületamatu; Aligipääsetav; Ikoostalitlusvõimeline ja Re-kasutatav.
„Leitav” tähendab, et teaduslikud andmed, mis on avaldatud teaduslike leidude aluseks olevate tõendite osana või mis on toodetud riiklikult rahastatud uurimistöö tulemusena, peaksid olema teistele leidmiseks ja kasutamiseks kättesaadavad. Andmetel peab olema püsiv ja üheselt mõistetav identifikaator, samuti piisavalt rikkalikud metaandmed, et võimaldada avastada.
"Mõnede andmete kaitsmiseks on mõjuvad põhjused," ütleb Simon Hodson, "kuid kui need kaalutlused ei kehti, tähendavad FAIRi põhimõtted, et teil peaks olema juurdepääs andmetele veebi kaudu, võib-olla volitusega, kui on turvaprobleeme. . Oluline on see, et FAIR-i põhimõtted nõuavad, et teadlastel peaks olema juurdepääs uurimisandmetele programmiliselt, see tähendab ka oma masinate kaudu. Asi pole ainult selles, et saate andmeid hankida ja need alla laadida: ideaalis peaksite saama neid päringuid teha arvutikoodiga.
I tähistab FAIRis „koostalitlusvõimet” – see tähendab, et saate kombineerida erinevatest allikatest pärit andmeid: see sõltub suuresti metaandmete standardite olemasolust ja kokkulepitud terminoloogiast või sõnavarast. Näiteks konkreetse riigi sotsiaaluuringu metaandmed selgitavad selgelt kasutatud vanusekategooriaid või sotsiaalmajanduslikke kategooriaid ja kategooriate piiride asukohta, et andmeid oleks lihtne võrrelda sotsiaaluuringu andmetega. teises riigis.
R tähistab korduvkasutatavust: see hõlmab litsentsi olemasolu, mis lubab inimestel andmeid taaskasutada ja sätestab selgelt korduskasutamise tingimused. See tähendab ka teabe omamist andmete päritolu kohta (näiteks kuidas neid koguti, milliseid kohandusi või kalibreerimisi kasutati, millist edasist töötlemist ja andmete puhastamist on tehtud jne), et teadlased mõistaksid andmete võimalikke tugevaid külgi ja piiranguid. andmeid ja kasutage neid enesekindlalt.
FAIRi andmed on ka täielikult AI valmis. Et kasutada masinõpet mustrite tuvastamiseks ja erinevate andmekogumite tulemuste ennustamiseks, on oluline, et andmekogumis oleksid definitsioonid erinevate muutujate jaoks ja definitsioonid peavad olema hõlpsasti juurdepääsetavad.
„Kui andmed ja nendega seotud teenused on AUSAD, siis on kõik kirjeldatud nii, et arvuti – ja igaüks, kes seda koodi kasutab – teaks, millist definitsiooni mõiste ja sellega seotud muutuja jaoks on kasutatud, kuidas mõõtmised on saadud ning väärtustab ennast. Seejärel saame andmekoodiga suhelda, võib-olla selle lagundada, võtta alamhulga, kombineerida seda muude andmetega. Kui andmed on AUSAD, saab seda teha palju tõhusamalt ning analüüsist ja uurimisest on kasu, ”ütleb Simon Hodson.
Idee standardiseeritud sõnavarast, mille abil väljendada põhimõisteid erinevates teadusvaldkondades, pole sugugi uus. The Rahvusvaheline Puhta ja Rakenduskeemia Liit (IUPAC), ISC liige, on reageerinud rahvusvahelise standardimise vajadusele keemias alates selle asutamisest 1919. aastal. Tänapäeval on hädavajalik, et standardsed sõnavarad kohandataks digiajastuga ja muudetaks AUSAKS. Andmete dokumenteerimise algatuse raames korraldatud seminari tulemusena avaldas Simon Coxi (endine CODATA täitevkomitee liige ja terminoloogiaekspert) juhitud rühm "Kümme lihtsat reeglit sõnavaramessi tegemiseks'.
Neid juhiseid järgides töötab CODATA praegu FAIRi sõnavara kallal Ohuteabe profiilid ISC avaldas 2021. aasta oktoobris. Sellega luuakse kõigi kirjeldatud ohtude jaoks veebipõhine terminoloogia, mis tehakse kõigile kasutamiseks kättesaadavaks GitHubis ja teenuse Research Vocabularies Australia kaudu. See tähendab, et valitsused, kes töötavad välja oma riskide vähendamise ja juhtimise strateegiaid ja meetmeid, saavad andmeid kiiresti võrrelda näiteks oma statistikaga katastroofide kahjude või aruandlusraamistike kohta.
CODATA töötab ka FAIRi sõnavara kallal mitme erineva ISC liikmega, näiteks Rahvusvahelise Rahvastiku Teadusliku Uurimise Liiduga (IUSSP). Demograafia on andmerikas valdkond ja on säästva inimarengu mõistmiseks väga oluline. Muutes rahvastikuteaduse põhiterminoloogiat FAIR-i, aitab IUSSP muuta demograafilised andmed kasulikumaks nii statistikaagentuuridele ja sotsiaalteadlastele kui ka neile, kes kasutavad selliseid andmeid paljudes rahvastikuandmeid kasutavates valdkondades, sealhulgas enamikus säästva arenguga seotud valdkondades. arengueesmärgid (SDG).
CODATA teeb ka uue kaheaastase projekti raames samasugust tööd IUPACiga.Maailmamess: Ülemaailmne koostöö FAIRi andmepoliitika ja praktika vallas”, mida rahastab Euroopa Komisjon oma Euroopa raamprogramm Horisont. Koordineerib CODATAKoos Uurimisandmete liit Assotsiatsiooni kui peamise partnerina töötab WorldFAIR projekt üheteistkümne domeeni- ja valdkonnaülese juhtumiuuringuga, et edendada FAIRi andmepõhimõtete rakendamist, eelkõige koostalitlusvõime põhimõtete rakendamist ning töötada välja soovituste kogum ja raamistik FAIRi jaoks. distsipliinide või valdkondadevaheliste uurimisvaldkondade hindamine. WorldFAIR moodustab CODATA panuse ISC projekti tuumiku Andmete toimimine domeenideüleste suurte väljakutsete jaoks.
IUPAC juhib keemia juhtumiuuringut, uurides, kuidas muuta IUPACi kureeritud teabevarad ja terminoloogiad digitaliseerimise ajastu ja FAIRi andmete jaoks sobivaks. IUPAC tegeleb ka teiste WorldFAIRi nanomaterjalide ja geokeemia juhtumiuuringutega.
Teine WorldFAIRi partner on Drexeli Ülikool, USA, kes juhtis Salud Urbana en América Latina (“Linnatervis Ladina-Ameerikas”) (SALURBAL) projekti. SALURBAAL töötas välja a mitut riiki hõlmav andmestik selliste valdkondade kohta nagu demograafilised omadused, suremusnäitajad, tervisekäitumine ja -riskid, sotsiaalne keskkond ja ehitatud keskkond, mis võimaldab võrrelda Ladina-Ameerika linnu ja linnaosasid. See hämmastav ressurss võimaldab teha poliitikaga seotud uuringuid tervise ja tervisealase ebavõrdsuse põhjuste kohta piirkonna linnades. SALURBAL on andmete ühtlustamisega juba palju tööd teinud. WorldFAIR aitab seda tööd rohkem valgustada ja annab soovitusi FAIRi terminoloogiate kohta linnatervishoius.
Võite olla huvitatud ka

CAG-CEPT, CODATA ja UHWB taskuhäälingusaadete sari teemal „Andmeteadmised linnasüsteemidele”
Data-Knowledge-Action for Urban Systems taskuhäälingusaadete seerias uuritakse süsteeme, mida kasutatakse intelligentsete linnasüsteemide ehitamiseks. Sari kajastab süstemaatilisi muudatusi, mis on vajalikud selleks, et linnad muutuksid kohanemisvõimelisteks ja intelligentseteks linna heaoluga toimetulekuks. Seda haldab rakendusgeomaatika keskus, CODATA ning linnatervise ja heaolu programm (UHWB).
15. ja 16. veebruaril andis Simon Hodson infotunni CODATA tööst osana ISC liikmetele suunatud teadmiste jagamise sessioonist. Teaduse ja tehnoloogia lähenemine digitaalajastul.
Lisateavet projekti WorldFAIR, CODATA töö kohta FAIRi sõnavarade kallal ning erinevate uurimisvaldkondade algatuste kohta andmete ja teabevarade FAIR-i muutmiseks leiate aadressilt 2022. aasta rahvusvaheline andmenädal, 20.–23. juuni.
Pildi autor École polytechnique – J.Barande Flickri kaudu.
Related Items



Autoritaarsetest ohtudest rahastamise erinevusteni: ülemaailmse teaduse peamised väljakutsed
12.06.2023

























COP23 kliimamuutuste kõrvalsündmus – millal ja kus saavutatakse elamiskõlblikkuse piirid?
14.11.2017







Juhtivad teadusrühmad nõuavad suurandmete maailmas avatud andmete osas ülemaailmset kokkulepet
07.12.2015
Avatud juurdepääs teadusandmetele ja -kirjandusele ning uuringute hindamine mõõdikute järgi
14.10.2014