
Les données qui sous-tendent la recherche scientifique sont ce qui alimente les progrès de la compréhension scientifique. Ces ensembles de données contiennent des indices vitaux sur bon nombre des questions les plus urgentes auxquelles sont confrontés les scientifiques aujourd'hui, et peuvent jeter un nouvel éclairage sur les découvertes passées - soit en validant soit en invalidant les archives scientifiques existantes, et en ouvrant des possibilités pour de nouvelles recherches et de nouvelles connaissances. Cependant, ce type d'informations disparaît souvent au cours du processus de publication des découvertes scientifiques, soit parce que les données ne sont pas partagées, soit parce qu'elles ne sont pas mises à disposition dans un format facile d'accès et d'interrogation.
"En science, beaucoup de travaux merveilleux finissent par être publiés sous forme de documents PDF. Être capable d'imprimer et de lire un article est formidable pour les humains, mais beaucoup d'informations qui ont servi à construire ce qui est rapporté dans le PDF finissent par être cachées. Si nous voulons avoir une vue d'ensemble et examiner toutes les expériences qui ont été faites et qui ont été rapportées dans la littérature concernant un certain processus ou réaction, il nous est très difficile d'extraire toutes ces informations de tous ces PDF. ', explique Simon Hodson, directeur exécutif de ISC-CODATA.
Selon les mots du chimiste Peter Murray-Rust, obtenir des informations utiles à partir de fichiers PDF peut être comme "reconstruire une vache à partir d'un hamburger de bœuf".
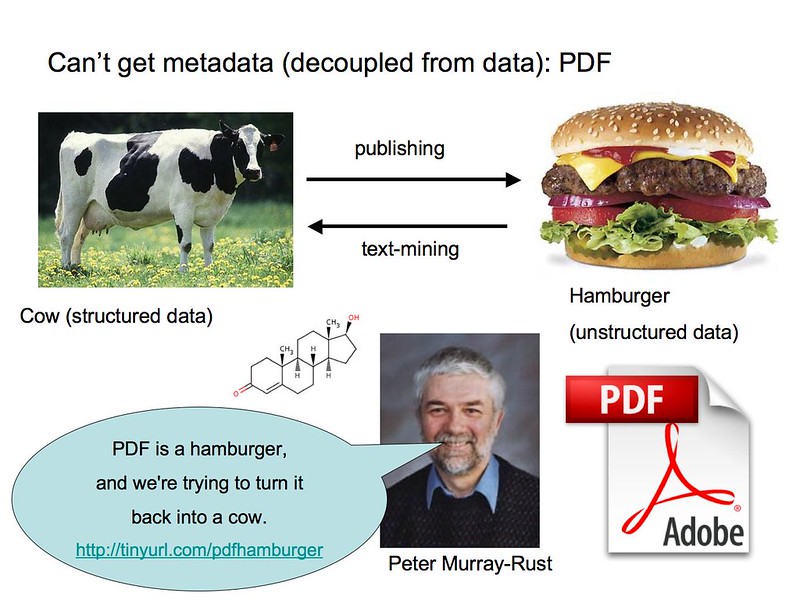
Il existe une multitude de données scientifiques qui ont été produites au cours de nombreuses années de recherche, mais dans de nombreux cas, il n'est pas possible - et certainement pas facile - pour trouver ces données et les interroger afin de les comparer avec d'autres découvertes ou travaux en cours. Face à cette énigme, et conformément à l'impératif de la science ouverte, les chercheurs s'efforcent actuellement de favoriser la science axée sur les données grâce à des cadres qui prennent en charge l'accessibilité et l'interopérabilité des données.
L'une des approches les plus récentes et les plus importantes pour y parvenir est FAIR, qui encapsule ce que les données doivent être pour être aussi utilisables et utiles que possible : les données FAIR sont des données qui sont Findémodable; Aaccessible ; IInteropérable et Re-utilisable.
« Trouvable » signifie que les données scientifiques publiées dans le cadre des preuves sous-jacentes aux découvertes scientifiques, ou produites à la suite de recherches financées par des fonds publics, doivent être disponibles pour que d'autres puissent les trouver et les utiliser. Les données doivent avoir un identifiant persistant et sans ambiguïté, ainsi que des métadonnées suffisamment riches pour permettre la découverte.
« Il y a de bonnes raisons de protéger certaines données », déclare Simon Hodson, « mais là où ces considérations ne s'appliquent pas, les principes FAIR signifient que vous devriez pouvoir accéder aux données sur le Web, peut-être avec une autorisation en cas de problèmes de sécurité. . Fondamentalement, les principes FAIR soutiennent que les scientifiques devraient pouvoir accéder aux données de recherche par programmation, c'est-à-dire également par leurs machines. Ce n'est pas seulement que vous pouvez obtenir les données et les télécharger : vous devriez idéalement pouvoir les interroger avec un code informatique.
Le i dans FAIR fait référence à « interopérable » - ce qui signifie que vous pouvez combiner des données provenant de différentes sources : cela dépend en grande partie de l'existence de normes pour les métadonnées et de terminologies ou de vocabulaires convenus. Par exemple, les métadonnées d'une enquête sociale d'un pays donné expliqueraient clairement les catégories d'âge ou les catégories socio-économiques qui ont été utilisées, et où se situent les limites des catégories, de sorte que les données puissent être facilement comparées aux données d'une enquête sociale. dans un autre pays.
R signifie réutilisabilité : cela implique d'avoir une licence qui permet aux personnes de réutiliser les données et énonce clairement les conditions de toute réutilisation. Cela signifie également avoir des informations sur la provenance des données (par exemple, comment elles ont été recueillies, quels ajustements ou étalonnages ont été utilisés, quels traitements et nettoyages ultérieurs les données ont subis, etc.) afin que les chercheurs puissent comprendre les points forts et les limites potentiels de les données et les utiliser en toute confiance.
Les données FAIR sont également « entièrement prêtes pour l'IA ». Afin d'utiliser l'apprentissage automatique pour identifier des modèles et commencer à prédire les résultats dans différents ensembles de données, il est essentiel d'avoir des définitions pour différentes variables dans l'ensemble de données, et les définitions doivent être facilement accessibles.
"Lorsque les données et les services associés sont FAIR, alors tout est décrit de sorte que l'ordinateur - et toute personne utilisant le code - sache quelle définition a été utilisée pour le concept et la variable associée, la manière dont les mesures ont été obtenues, et la valeurs elles-mêmes. Ensuite, nous pouvons interagir avec le code de données, peut-être le décomposer, prendre un sous-ensemble, le combiner avec d'autres données. Si les données sont FAIR, cela peut être fait beaucoup plus efficacement et l'analyse et la recherche elles-mêmes en bénéficient », déclare Simon Hodson.
L'idée d'avoir des vocabulaires normalisés avec lesquels exprimer les concepts de base dans divers domaines de la science n'est en aucun cas nouvelle. La Union internationale de chimie pure et appliquée (IUPAC), membre de l'ISC, répond au besoin de normalisation internationale en chimie depuis sa fondation en 1919. Aujourd'hui, il est impératif que les vocabulaires standards soient adaptés à l'ère numérique et soient eux-mêmes rendus FAIR. À la suite d'un atelier organisé avec l'initiative Data Documentation, un groupe dirigé par Simon Cox (ancien membre du comité exécutif de CODATA et expert de l'utilisation des terminologies) a publié 'Dix règles simples pour faire un vocabulaire FAIR".
Suivant ces lignes directrices, CODATA travaille actuellement sur un vocabulaire FAIR pour les Profils d'informations sur les dangers publié par l'ISC en octobre 2021. Cela créera une terminologie Web pour tous les dangers décrits, qui sera mise à disposition sur GitHub et via le service Research Vocabularies Australia, à l'usage de tous. Cela signifie que les gouvernements développant leurs stratégies et actions sur la réduction et la gestion des risques seront en mesure de comparer rapidement les données avec leurs propres statistiques sur les pertes dues aux catastrophes ou les cadres de reporting, par exemple.
CODATA travaille également sur les vocabulaires FAIR avec plusieurs membres différents de l'ISC, comme l'Union internationale pour l'étude scientifique de la population (UIESP). La démographie est un domaine riche en données et est très pertinente pour comprendre le développement humain durable. En rendant les terminologies clés en science de la population FAIR, l'UIESP contribuera à rendre les données démographiques plus utiles pour les agences statistiques et les spécialistes des sciences sociales, ainsi que pour ceux qui utilisent ces données dans les nombreux domaines d'études qui utilisent des données démographiques, y compris la plupart des domaines liés au développement durable. Objectifs de développement (ODD).
CODATA entreprendra également un travail similaire avec l'IUPAC dans le cadre du nouveau projet de deux ans 'FOIRE MONDIALE: Coopération mondiale sur la politique et la pratique des données FAIR', financé par la Commission européenne à travers son Programme-cadre Horizon Europe. Coordonné par CODATA, Avec le Alliance de données de recherche association en tant que partenaire majeur, le projet WorldFAIR travaillera avec un ensemble de onze études de cas de domaines et interdomaines pour faire avancer la mise en œuvre des principes de données FAIR, en particulier ceux d'interopérabilité, et pour développer un ensemble de recommandations et un cadre pour FAIR évaluation dans un ensemble de disciplines ou de domaines de recherche transdisciplinaires. WorldFAIR constituera le cœur de la contribution de CODATA au projet ISC Faire fonctionner les données pour les grands défis interdomaines.
L'IUPAC dirige l'étude de cas sur la chimie, en examinant comment rendre les actifs d'information et les terminologies que l'IUPAC organise appropriés à l'ère de la numérisation et des données FAIR. L'IUPAC participera également à d'autres études de cas WorldFAIR sur les nanomatériaux et la géochimie.
Un autre partenaire de WorldFAIR est l'Université Drexel, aux États-Unis, qui a dirigé le projet Salud Urbana en América Latina (« Santé urbaine en Amérique latine ») (SALURBAL). SALURBAL a développé un ensemble de données multi-pays sur des domaines tels que les caractéristiques démographiques, les taux de mortalité, les comportements et les risques de santé, l'environnement social et l'environnement bâti, permettant de comparer les villes et les quartiers au sein des villes d'Amérique latine. Cette ressource étonnante permettra des recherches pertinentes pour les politiques sur les moteurs de la santé et les inégalités en matière de santé dans les villes de la région. SALURBAL a déjà effectué un travail approfondi sur l'harmonisation des données. WorldFAIR aidera à faire la lumière sur ce travail et fera des recommandations pour les terminologies FAIR en santé urbaine.
Vous pourriez également être intéressé par

Série de podcasts CAG-CEPT, CODATA et UHWB sur 'Data-Knowledge-Action for Urban Systems
La série de podcasts Data-Knowledge-Action for Urban Systems explore les systèmes utilisés pour construire des systèmes urbains intelligents. La série réfléchit sur les changements systématiques nécessaires pour que les villes deviennent adaptatives et intelligentes pour gérer le bien-être urbain. Il est hébergé par le Centre de géomatique appliquée, CODATA et Urban Health and Wellbeing Program (UHWB).
Les 15 et 16 février, Simon Hodson a donné un briefing sur le travail de CODATA dans le cadre de la session de partage des connaissances pour les membres de l'ISC sur Convergence de la science et de la technologie à l'ère numérique.
Vous pouvez en savoir plus sur le projet WorldFAIR, sur le travail de CODATA sur les vocabulaires FAIR et sur les initiatives dans diverses disciplines de recherche pour rendre les actifs de données et d'information FAIR sur Semaine internationale des données 2022, 20-23 juin.
Image par École polytechnique – J.Barande via Flickr.
Articles Similaires



Des menaces autoritaires aux disparités de financement : les principaux défis de la science mondiale
12.06.2023



WorldFAIR : Coopération mondiale sur la politique et les pratiques de FAIR en matière de données
03.06.2022


CODATA et ISC célèbrent la métrologie à l'ère numérique lors de la Journée mondiale de la métrologie
20.05.2022














Données sur les pertes en cas de catastrophe dans le suivi de la mise en œuvre du cadre de Sendai
10.05.2019



Poste vacant : Directeur exécutif du Système mondial de données de l'ICSU (WDS) (republié)
19.06.2018


Ouverture d'un bureau international de technologie du Système mondial de données de l'ICSU au Canada
12.04.2018

L'IAMAS exhorte les États-Unis à continuer de soutenir les systèmes d'observation de la Terre
04.12.2017


Le Belmont Forum annonce Mustapha Mokrane comme nouveau co-responsable de l'Open Data Initiative
06.11.2017





Comité de coordination stratégique ad hoc sur l'information et les données (Rapport SCCID)
11.01.2013
Ouverture du bureau du programme international du nouveau système mondial de données de l'ICSU
09.05.2012
Note consultative sur l'accès aux données partagées pour réduire les inégalités mondiales
11.01.2012
Le CIUS lance un programme d'action avant le Sommet mondial sur la société de l'information
17.07.2003