
Данные, лежащие в основе научных исследований, — это то, что способствует прогрессу в научном понимании. Эти наборы данных содержат жизненно важные ключи к разгадке многих наиболее насущных вопросов, стоящих сегодня перед учеными, и могут пролить новый свет на прошлые открытия, подтверждая или опровергая существующие научные данные и открывая возможности для новых исследований и нового понимания. Однако такая информация часто исчезает в процессе публикации научных результатов либо потому, что данные не распространяются, либо не предоставляются в формате, удобном для доступа и изучения.
«В науке многие замечательные работы публикуются в виде PDF-документов. Возможность распечатать и прочитать статью полезна для людей, но большая часть информации, которая использовалась для построения того, что сообщается в PDF, в конечном итоге оказывается скрытой. Если мы хотим получить общую картину и посмотреть на все эксперименты, которые были проведены и описаны в литературе, относящиеся к определенному процессу или реакции, нам очень сложно извлечь всю эту информацию из всех этих PDF-файлов. , — объясняет Саймон Ходсон, исполнительный директор ISC-КОДАТА.
По словам химика Питера Мюррея-Раста, получение полезной информации из PDF-файлов может быть похоже на «реконструкцию коровы из говяжьего бургера».
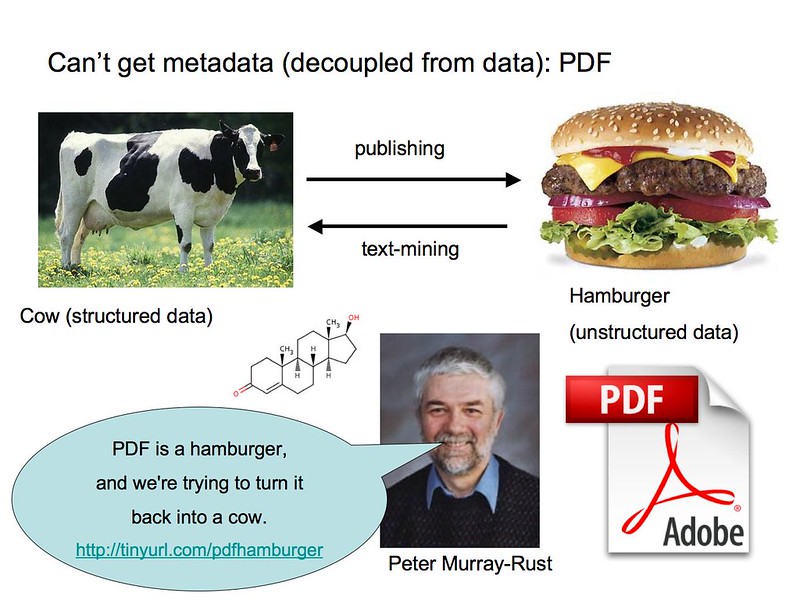
В ходе многолетних исследований было получено множество научных данных, но во многих случаях это невозможно. - и конечно не просто - найти эти данные и запросить их, чтобы сравнить их с другими результатами или текущей работой. Столкнувшись с этой загадкой и в соответствии с императивом открытой науки, исследователи в настоящее время работают над дальнейшим внедрением науки, основанной на данных, с помощью сред, поддерживающих доступность и совместимость данных.
Одним из последних и наиболее известных подходов к этому является FAIR, который инкапсулирует то, какими должны быть данные, чтобы быть максимально полезными и ценными: FAIR данные — это данные, которые Fневероятный; Aдоступный; Iинтероперабельный и Rэлектронное использование.
«Доступность для поиска» означает, что научные данные, опубликованные как часть подтверждения научных результатов или полученные в результате исследований, финансируемых государством, должны быть доступны для поиска и использования другими лицами. Данные должны иметь постоянный и недвусмысленный идентификатор, а также достаточно подробные метаданные, чтобы их можно было обнаружить.
«Есть веские причины для защиты некоторых данных, — говорит Саймон Ходсон, — но там, где эти соображения неприменимы, принципы FAIR означают, что вы должны иметь доступ к данным через Интернет, возможно, с авторизацией, если есть проблемы с безопасностью. . Важно отметить, что принципы FAIR утверждают, что ученые должны иметь возможность доступа к исследовательским данным программно, то есть также с помощью своих машин. Дело не только в том, что вы можете получить данные и загрузить их: в идеале вы должны иметь возможность запрашивать их с помощью компьютерного кода».
Буква i в слове FAIR означает «интероперабельность» — это означает, что вы можете комбинировать данные из разных источников: это во многом зависит от наличия стандартов для метаданных и согласованной терминологии или словарей. Например, метаданные для социального опроса из данной страны будут четко объяснять возрастные категории или социально-экономические категории, которые использовались, и где проходят границы категорий, чтобы данные можно было легко сравнивать с данными социального опроса. в другой стране.
R означает возможность повторного использования: это включает в себя наличие лицензии, которая позволяет людям повторно использовать данные и четко определяет условия любого повторного использования. Это также означает наличие информации о происхождении данных (например, как они были собраны, какие корректировки или калибровки использовались, какой дальнейшей обработке и очистке подвергались данные и т. д.), чтобы исследователи могли понять потенциальные сильные стороны и ограничения данные и использовать их с уверенностью.
Данные FAIR также «полностью готовы к ИИ». Чтобы использовать машинное обучение для выявления закономерностей и начала прогнозирования результатов для разных наборов данных, важно иметь определения для различных переменных в наборе данных, и определения должны быть легко доступны.
«Когда данные и связанные с ними услуги являются ЧЕСТНЫМИ, тогда все описывается так, чтобы компьютер — и любой, кто использует код — знал, какое определение использовалось для понятия и связанной переменной, каким образом были получены измерения и ценит себя. Затем мы можем взаимодействовать с кодом данных, возможно, разлагая его, беря подмножество, комбинируя его с другими данными. Если данные ЧЕСТНЫ, это можно сделать гораздо эффективнее, а сам анализ и исследование принесут пользу», — говорит Саймон Ходсон.
Идея стандартизированных словарей, с помощью которых можно выразить основные понятия в различных областях науки, отнюдь не нова. Международный союз теоретической и прикладной химии (IUPAC), член ISC, отвечает на потребность в международной стандартизации в химии с момента своего основания в 1919 году. Сегодня крайне важно, чтобы стандартные словари были адаптированы к цифровой эпохе и сами были сделаны ЧЕСТНЫМИ. В результате семинара, организованного в рамках инициативы Data Documentation, группа под руководством Саймона Кокса (бывший член исполнительного комитета CODATA и эксперт по использованию терминологии) опубликовала «Десять простых правил составления словарного запаса FAIR.
Следуя этим рекомендациям, CODATA в настоящее время работает над словарем FAIR для Профили информации об опасностях опубликовано ISC в октябре 2021 года. Это позволит создать веб-терминологию для всех описанных опасностей, которая будет доступна на GitHub и через службу Research Vocabularies Australia для всех желающих. Это означает, что правительства, разрабатывающие свои стратегии и действия по снижению рисков и управлению ими, смогут быстро сравнивать данные, например, со своими собственными статистическими данными об ущербе от стихийных бедствий или системами отчетности.
CODATA также работает над словарями FAIR с несколькими различными членами ISC, например, с Международным союзом научных исследований населения (IUSSP). Демография — это богатая данными область, которая имеет большое значение для понимания устойчивого человеческого развития.. Делая ключевые термины в науке о народонаселении FAIR, IUSSP будет способствовать тому, чтобы демографические данные стали более полезными для статистических агентств и социологов, а также для тех, кто использует такие данные во многих областях исследований, в которых используются данные о народонаселении, включая большинство областей, связанных с устойчивым развитием. Цели развития (ЦУР).
CODATA также проведет аналогичную работу с IUPAC в рамках нового двухлетнего проекта «Всемирная выставка: Глобальное сотрудничество в области политики и практики использования данных FAIR', финансируется Европейской комиссией через ее Рамочная программа Horizon Europe. Координируется КОДАТА, С Альянс исследований данных Ассоциация в качестве основного партнера, проект WorldFAIR будет работать с набором из одиннадцати доменных и междисциплинарных тематических исследований для продвижения реализации принципов данных FAIR, в частности, для функциональной совместимости, а также для разработки набора рекомендаций и структуры для FAIR. оценка в наборе дисциплин или междисциплинарных областях исследований. WorldFAIR станет основой вклада CODATA в проект ISC. Как заставить данные работать для решения междоменных задач.
IUPAC возглавляет тематическое исследование по химии, изучая, как сделать информационные ресурсы и терминологию, которые курирует IUPAC, подходящими для эпохи оцифровки и данных FAIR. IUPAC также примет участие в других тематических исследованиях WorldFAIR по наноматериалам и геохимии.
Еще одним партнером WorldFAIR является Университет Дрекселя, США, который руководил проектом Salud Urbana en América Latina («Городское здоровье в Латинской Америке») (SALURBAL). САЛУРБАЛ разработал набор данных по нескольким странам по таким областям, как демографические характеристики, уровень смертности, поведение и риски для здоровья, социальная среда и искусственная среда, что позволяет сравнивать города и районы внутри городов по всей Латинской Америке. Этот удивительный ресурс позволит проводить актуальные для политики исследования движущих сил здоровья и неравенства в отношении здоровья в городах региона. SALURBAL уже проделал большую работу по гармонизации данных. WorldFAIR поможет пролить больше света на эту работу и даст рекомендации по терминологии FAIR в области городского здравоохранения.
Вы также можете быть заинтересованы в

Серия подкастов CAG-CEPT, CODATA и UHWB на тему «Данные-знания-действия для городских систем»
Серия подкастов Data-Knowledge-Action for Urban Systems исследует системы, используемые для создания интеллектуальных городских систем. Сериал отражает систематические изменения, необходимые для того, чтобы города стали адаптивными и разумными для обеспечения благополучия в городах. Он проводится Центром прикладной геоматики, CODATA и Программой городского здоровья и благополучия (UHWB).
15 и 16 февраля Саймон Ходсон провел брифинг о работе CODATA в рамках сессии по обмену знаниями для членов ISC по Конвергенция науки и техники в эпоху цифровых технологий.
Вы можете узнать больше о проекте WorldFAIR, о работе CODATA над словарями FAIR и об инициативах в различных исследовательских дисциплинах, направленных на то, чтобы сделать данные и информационные активы FAIR на Международная неделя данных 2022 г., 20-23 июня.
Изображение École polytechnique – J.Barande через Flickr.
Сопутствующие товары






WorldFAIR: глобальное сотрудничество в области политики и практики использования данных FAIR
03.06.2022


CODATA и ISC отмечают Всемирный день метрологии в области метрологии в эпоху цифровых технологий
20.05.2022














Данные о потерях в результате бедствий при мониторинге реализации Сендайской рамочной программы
10.05.2019













Африканская открытая научная платформа усилит влияние открытых данных на науку и общество
12.12.2016
Ведущие научные группы призывают к глобальному соглашению об открытых данных в мире больших данных
07.12.2015
Новая система World Data System ICSU открывает новый международный программный офис в Токио
16.05.2012
МСНС запускает Программу действий в преддверии Всемирного саммита по информационному обществу
17.07.2003