
Дані, що лежать в основі наукових досліджень, — це те, що сприяє розвитку наукового розуміння. Ці набори даних містять життєво важливі ключі до багатьох найактуальніших питань, що стоять перед науковцями сьогодні, і можуть пролити нове світло на минулі висновки – або підтверджуючи, або скасовувати наявні записи науки, і відкриваючи можливості для нових досліджень і нового розуміння. Однак така інформація часто зникає під час опублікування наукових висновків через те, що дані не передаються, або вони недоступні у легкодоступному форматі.
«У науці багато чудових робіт публікуються у форматі PDF-документів. Можливість друкувати та читати статтю чудово підходить для людей, але багато інформації, яка була використана для створення того, що повідомляється у PDF-файлі, в кінцевому підсумку приховано. Якщо ми хочемо отримати велике зображення та подивитися на всі експерименти, які були проведені та про які повідомлялося в літературі, що стосуються певного процесу чи реакції, нам дуже важко витягти всю цю інформацію з усіх цих PDF-файлів. », – пояснює Саймон Ходсон, виконавчий директор ISC-CODATA.
За словами хіміка Пітера Мюррея-Раста, отримання корисної інформації з PDF-файлів може бути схоже на «реконструкцію корови з бургера з яловичини».
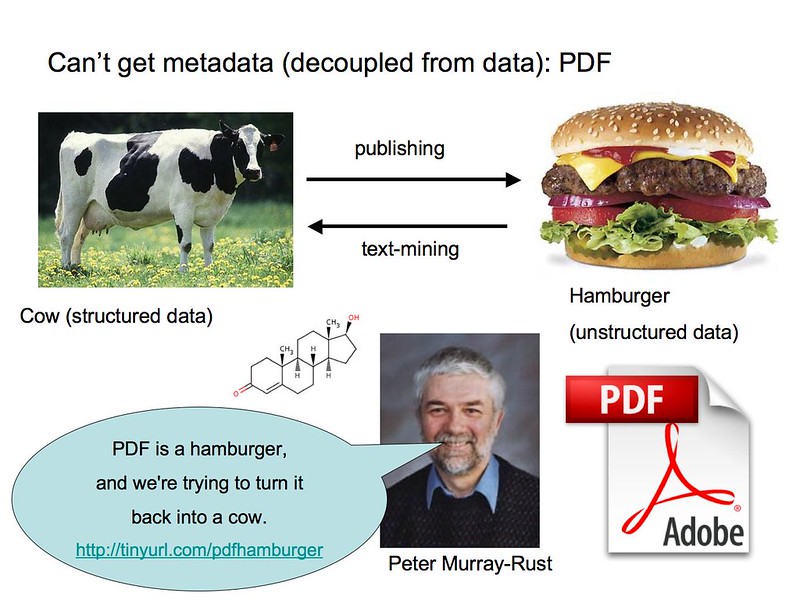
Існує велика кількість наукових даних, які були отримані в ході багаторічних досліджень, але в багатьох випадках це неможливо - і звичайно не легко - щоб знайти ці дані та запитати їх, щоб порівняти їх з іншими результатами чи поточною роботою. Зіткнувшись з цією загадкою та відповідно до імперативу відкритої науки, дослідники наразі працюють над тим, щоб далі впровадити науку, керовану даними, за допомогою структур, які підтримують доступність та сумісність даних.
Одним з останніх і найвідоміших підходів до цього є FAIR, який інкапсулює, які дані повинні бути, щоб бути максимально корисними та цінними: FAIR дані – це дані, які Fнепрохідний; Aдоступний; Iсумісний і Rелектронне використання.
«Можливість знайти» означає, що наукові дані, які опубліковані як частина доказів, що підтверджують наукові висновки, або отримані в результаті досліджень, що фінансуються державою, повинні бути доступні для пошуку та використання іншими. Дані повинні мати постійний і однозначний ідентифікатор, а також достатньо багаті метадані, щоб уможливити виявлення.
«Існують вагомі причини для захисту деяких даних, — каже Саймон Ходсон, — але якщо ці міркування не застосовуються, принципи FAIR означають, що ви повинні мати доступ до даних через Інтернет, можливо, з авторизацією, якщо є проблеми з безпекою. . Важливо те, що принципи FAIR підтверджують, що вчені повинні мати доступ до даних досліджень програмно, тобто також за допомогою своїх машин. Справа не тільки в тому, що ви можете отримати дані та завантажити їх: в ідеалі ви повинні мати можливість запитувати їх за допомогою комп’ютерного коду».
I в FAIR означає «сумісність» — це означає, що ви можете комбінувати дані з різних джерел: це значною мірою залежить від наявності стандартів для метаданих та узгодженої термінології чи словників. Наприклад, метадані соціального опитування з певної країни чітко пояснюють вікові категорії або соціально-економічні категорії, які були використані, і де проходять межі категорій, щоб дані можна було легко порівняти з даними соціального опитування. в іншій країні.
R означає можливість повторного використання: це включає наявність ліцензії, яка дозволяє людям повторно використовувати дані та чітко вказує умови будь-якого повторного використання. Це також означає наявність інформації про походження даних (наприклад, як вони були зібрані, які налаштування або калібрування були використані, яка подальша обробка та очищення даних зазнали тощо), щоб дослідники могли зрозуміти потенційні сильні сторони та обмеження дані та впевнено користуйтеся ними.
Дані FAIR також є «повністю готовими до штучного інтелекту». Щоб використовувати машинне навчання для визначення закономірностей і початку прогнозування результатів у різних наборах даних, важливо мати визначення для різних змінних у наборі даних, а визначення мають бути легко доступними.
«Коли дані та пов’язані послуги є ЧЕСНИМИ, тоді все описується так, щоб комп’ютер – і будь-хто, хто використовує код – знав, яке визначення було використано для поняття та пов’язаної змінної, спосіб, яким були отримані вимірювання, та самі цінності. Тоді ми можемо взаємодіяти з кодом даних, можливо, розкладаючи його, беручи підмножину, об’єднуючи її з іншими даними. Якщо дані є ЧЕСНИМИ, це можна зробити набагато ефективніше, а аналіз і дослідження принесуть користь», – каже Саймон Ходсон.
Ідея мати стандартизовані словники, за допомогою яких можна виражати основні поняття в різних галузях науки, аж ніяк не нова. The Міжнародний союз чистої та прикладної хімії (IUPAC), член ISC, реагує на потребу міжнародної стандартизації в хімії з моменту свого заснування в 1919 році. Сьогодні вкрай важливо, щоб стандартні словники були адаптовані до цифрової епохи і самі по собі були СПРАВЕДЛИВІ. В результаті семінару, організованого з ініціативою Data Documentation, група під керівництвом Саймона Кокса (колишнього члена виконавчого комітету CODATA і експерта з використання термінології) опублікувала «Десять простих правил створення словникового запасу.
Дотримуючись цих рекомендацій, CODATA зараз працює над словником FAIR для Профілі інформації про небезпеку опублікований ISC у жовтні 2021 року. Це створить веб-термінологію для всіх описаних небезпек, яка буде доступна на GitHub та через службу Research Vocabularies Australia, щоб усі могли користуватися. Це означає, що уряди, які розробляють свої стратегії та дії щодо зменшення ризиків та управління ними, зможуть швидко порівнювати дані зі своєю власною статистикою щодо втрат від стихійних лих або структурою звітності, наприклад.
CODATA також працює над словниками FAIR з кількома різними членами ISC, наприклад, з Міжнародним союзом для наукових досліджень населення (IUSSP). Демографія — це сфера, багата даними, і дуже актуальна для розуміння сталого людського розвитку. Роблячи ключову термінологію в народонауці FAIR, IUSSP сприятиме тому, щоб демографічні дані були кориснішими для статистичних агентств і суспільствознавців, а також тих, хто використовує такі дані в багатьох галузях досліджень, які використовують дані про населення, включаючи більшість областей, що стосуються сталого розвитку. Цілі розвитку (ЦУР).
CODATA також буде проводити подібну роботу з IUPAC в рамках нового дворічного проекту.Всесвітня ярмарок: Глобальне співробітництво щодо політики та практики даних FAIR', що фінансується Європейською комісією через її Рамкова програма Horizon Europe. Координує КОДАТА, С Research Data Alliance асоціації як головного партнера, проект WorldFAIR працюватиме з набором одинадцяти доменних та міждоменных тематичних досліджень для просування впровадження принципів даних FAIR, зокрема принципів сумісності, а також для розробки набору рекомендацій та основи для FAIR оцінювання за набором дисциплін або міждисциплінарних дослідницьких областей. WorldFAIR стане основою внеску CODATA в проект ISC Змусити дані працювати для великого міждоменного завдання.
IUPAC очолює тематичне дослідження хімії, розглядаючи, як зробити інформаційні активи та термінологію, яку курує IUPAC, відповідними епоху цифровізації та даних FAIR. IUPAC також співпрацюватиме з іншими тематичними дослідженнями WorldFAIR з наноматеріалів та геохімії.
Іншим партнером WorldFAIR є Університет Дрекселя, США, який очолив проект Salud Urbana en América Latina («Здоров’я міст у Латинській Америці») (SALURBAL). SALURBAL розробив a набір даних для кількох країн у таких областях, як демографічні характеристики, рівень смертності, поведінка та ризики для здоров’я, соціальне середовище та забудоване середовище, що дозволяє порівняти міста та райони в містах у Латинській Америці. Цей дивовижний ресурс дозволить проводити дослідження, пов’язані з політикою, щодо факторів здоров’я та нерівності у здоров’ї в містах регіону. SALURBAL вже провів велику роботу з гармонізації даних. WorldFAIR допоможе пролити більше світла на цю роботу та надасть рекомендації щодо термінології FAIR у міському здоров’ї.
Вас також можуть зацікавити

Серія подкастів CAG-CEPT, CODATA та UHWB на тему «Дані-знання-дія для міських систем
Серія подкастів Data-Knowledge-Action for Urban Systems досліджує системи, які використовуються для побудови інтелектуальних міських систем. У серіалі розповідається про систематичні зміни, необхідні для того, щоб міста стали адаптованими та розумними для забезпечення добробуту міст. Його проводять Центр прикладної геоматики, CODATA та Програма міського здоров’я та благополуччя (UHWB).
15 і 16 лютого Саймон Ходсон провів брифінг про роботу CODATA в рамках сесії обміну знаннями для членів ISC про Конвергенція науки і техніки в цифрову еру.
Ви можете дізнатися більше про проект WorldFAIR, про роботу CODATA над словниками FAIR та про ініціативи в різних наукових дисциплінах щодо створення даних та інформаційних ресурсів FAIR на Міжнародний тиждень даних 2022, 20-23 червня.
Зображення École Polytechnique – J.Barande через Flickr.
супутні товари
































Уряд Нової Зеландії дякує групам IRDR і CODATA за допомогу після землетрусу в Кайкурі 2016 року
23.02.2017

Африканська відкрита наукова платформа для посилення впливу відкритих даних для науки та суспільства
12.12.2016
Провідні наукові групи закликають до глобальної згоди щодо відкритих даних у світі великих даних
07.12.2015
Спеціальний стратегічний координаційний комітет з питань інформації та даних (Звіт SCCID)
11.01.2013
Консультативна примітка щодо доступу до спільних даних для зменшення глобальної нерівності
11.01.2012