
Los datos que sustentan la investigación científica son los que impulsan los avances en la comprensión científica. Estos conjuntos de datos contienen pistas vitales para muchas de las preguntas más apremiantes que enfrentan los científicos en la actualidad y pueden arrojar nueva luz sobre hallazgos anteriores, ya sea validando o invalidando el registro científico existente y abriendo posibilidades para nuevas investigaciones y nuevos conocimientos. Sin embargo, este tipo de información a menudo desaparece durante el proceso de publicación de hallazgos científicos, ya sea porque los datos no se comparten o porque no están disponibles en un formato que sea fácil de consultar y acceder.
'En ciencia, muchos trabajos maravillosos terminan publicados como documentos PDF. Poder imprimir y leer un artículo es excelente para los humanos, pero mucha información que se usó para construir lo que se informa en el PDF termina oculta. Si queremos obtener una visión general y ver todos los experimentos que se han realizado y se han informado en la literatura relacionada con un determinado proceso o reacción, es muy difícil para nosotros extraer toda esa información de todos esos archivos PDF. ', explica Simon Hodson, director ejecutivo de ISC-CODATA.
En palabras del químico Peter Murray-Rust, obtener información útil de los archivos PDF puede ser como "reconstruir una vaca a partir de una hamburguesa de ternera".
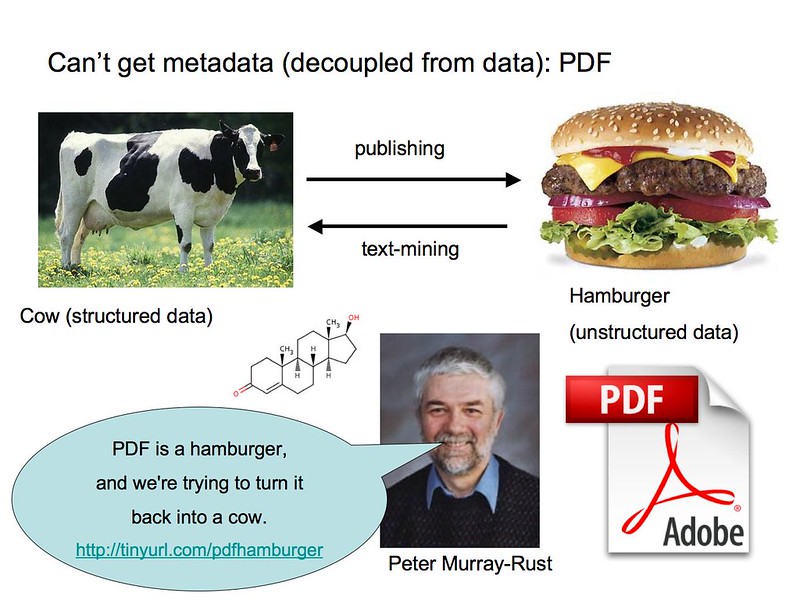
Hay una gran cantidad de datos científicos que se han producido en el curso de muchos años de investigación, pero en muchos casos, no es posible - y ciertamente no es fácil - para encontrar esos datos y consultarlos para compararlos con otros hallazgos o trabajos en curso. Frente a este dilema, y en línea con el imperativo de la ciencia abierta, los investigadores están trabajando actualmente para permitir aún más la ciencia basada en datos a través de marcos que respalden la accesibilidad y la interoperabilidad de los datos.
Uno de los enfoques más recientes y destacados para hacer esto es FAIR, que encapsula lo que los datos deben ser para que sean lo más utilizables y valiosos posible: los datos FAIR son datos que son Findestructible; Aaccesible; Iinteroperable y Re-utilizable.
'Encontrable' significa que los datos científicos que se publican como parte de la evidencia que respalda los hallazgos científicos, o producidos como resultado de una investigación financiada con fondos públicos, deben estar disponibles para que otros los encuentren y los utilicen. Los datos deben tener un identificador persistente e inequívoco, así como metadatos suficientemente ricos para permitir el descubrimiento.
“Hay buenas razones para proteger algunos datos”, dice Simon Hodson, “pero donde esas consideraciones no se aplican, los principios FAIR significan que debería poder acceder a los datos a través de la web, tal vez con autorización si hay problemas de seguridad. . Fundamentalmente, los principios FAIR sostienen que los científicos deberían poder acceder a los datos de investigación mediante programación, es decir, también mediante sus máquinas. No se trata solo de que pueda obtener los datos y descargarlos: idealmente, debería poder consultarlos con un código de computadora”.
La i en FAIR se refiere a 'interoperable', lo que significa que puede combinar datos de diferentes fuentes: esto depende en gran medida de tener estándares para los metadatos y terminologías o vocabularios acordados. Por ejemplo, los metadatos de una encuesta social de un país determinado explicarían claramente las categorías de edad o las categorías socioeconómicas que se han utilizado, y dónde se encuentran los límites de la categoría, de modo que los datos puedan compararse fácilmente con los datos de una encuesta social. en un país diferente.
R significa reutilización: esto incluye tener una licencia que permita a las personas reutilizar los datos y establece claramente las condiciones de cualquier reutilización. También significa tener información sobre la procedencia de los datos (por ejemplo, cómo se recopilaron, qué ajustes o calibraciones se usaron, qué procesamiento y limpieza posteriores se han realizado, etc.) para que los investigadores puedan comprender los puntos fuertes y las limitaciones potenciales de los datos y utilícelos con confianza.
Los datos FAIR también están 'totalmente preparados para IA'. Para usar el aprendizaje automático para identificar patrones y comenzar a predecir resultados en diferentes conjuntos de datos, es esencial tener definiciones para diferentes variables en el conjunto de datos, y las definiciones deben ser fácilmente accesibles.
“Cuando los datos y los servicios relacionados son FAIR, entonces todo se describe para que la computadora, y cualquier persona que use el código, sepa qué definición se ha utilizado para el concepto y la variable relacionada, la forma en que se han obtenido las medidas y el valores mismos. Entonces podemos interactuar con el código de datos, tal vez descomponiéndolo, tomando un subconjunto, combinándolo con otros datos. Si los datos son FAIR, esto se puede hacer de manera mucho más eficiente y el análisis y la investigación en sí mismos se benefician”, dice Simon Hodson.
La idea de tener vocabularios estandarizados con los que expresar los conceptos básicos en varios ámbitos de la ciencia no es nueva. los Unión Internacional de Química Pura y Aplicada (IUPAC), miembro del ISC, ha estado respondiendo a la necesidad de una estandarización internacional en química desde su fundación en 1919. Hoy en día, es imperativo que los vocabularios estándar se adapten a la era digital y sean justos. Como resultado de un taller organizado con la iniciativa Data Documentation, un grupo liderado por Simon Cox (ex miembro del Comité Ejecutivo de CODATA y experto en el uso de terminologías) publicó 'Diez reglas simples para hacer un vocabulario FAIR".
Siguiendo estos lineamientos, CODATA está trabajando actualmente en un vocabulario FAIR para la Perfiles de información sobre peligros publicado por el ISC en octubre de 2021. Esto creará una terminología basada en la web para todos los peligros descritos, que estará disponible en GitHub y a través del servicio Research Vocabularies Australia, para que cualquiera la use. Esto significa que los gobiernos que desarrollen sus estrategias y acciones sobre reducción y gestión de riesgos podrán comparar rápidamente los datos con sus propias estadísticas sobre pérdidas por desastres o marcos de informes, por ejemplo.
CODATA también está trabajando en vocabularios FAIR con varios miembros diferentes de ISC, como la Unión Internacional para el Estudio Científico de la Población (IUSSP). La demografía es un campo rico en datos y es muy relevante para comprender el desarrollo humano sostenible.. Al hacer que las terminologías clave en la ciencia de la población sean FAIR, la IUSSP contribuirá a hacer que los datos demográficos sean más útiles para las agencias estadísticas y los científicos sociales, así como para aquellos que usan dichos datos en los muchos campos de estudio que usan datos de población, incluida la mayoría de las áreas relacionadas con el Desarrollo Sostenible. Objetivos de Desarrollo (ODS).
CODATA también realizará un trabajo similar con IUPAC como parte del nuevo proyecto de dos años 'Feria Mundial: Cooperación global en política y práctica de datos FAIR', financiado por la Comisión Europea a través de su Programa Marco Horizonte Europa. Coordinado por CODATA, Con el Research Data Alliance asociación como socio principal, el proyecto WorldFAIR trabajará con un conjunto de once estudios de casos de dominio y entre dominios para avanzar en la implementación de los principios de datos FAIR, en particular los de interoperabilidad, y para desarrollar un conjunto de recomendaciones y un marco para FAIR evaluación en un conjunto de disciplinas o áreas de investigación interdisciplinarias. WorldFAIR formará el núcleo de la contribución de CODATA al Proyecto ISC Hacer que los datos funcionen para los grandes desafíos entre dominios.
IUPAC está liderando el estudio de caso de química, buscando cómo hacer que los activos de información y las terminologías que IUPAC selecciona sean apropiados para la era de la digitalización y los datos FAIR. La IUPAC también participará en otros estudios de casos de WorldFAIR sobre nanomateriales y geoquímica.
Otro socio de WorldFAIR es la Universidad de Drexel, EE. UU., que lideró el proyecto Salud Urbana en América Latina (SALURBAL). SALURBAL desarrolló un conjunto de datos de varios países sobre dominios como las características demográficas, las tasas de mortalidad, los comportamientos y riesgos de salud, el entorno social y el entorno construido, lo que permite realizar comparaciones de ciudades y barrios dentro de ciudades de América Latina. Este increíble recurso permitirá la investigación relevante para las políticas sobre los impulsores de la salud y las desigualdades en salud en las ciudades de la región. SALURBAL ya ha realizado un extenso trabajo de armonización de datos. WorldFAIR ayudará a arrojar más luz sobre este trabajo y hará recomendaciones para terminologías FAIR en salud urbana.
Usted también puede estar interesado en

Serie de podcasts CAG-CEPT, CODATA y UHWB sobre 'Datos-Conocimiento-Acción para sistemas urbanos
La serie de podcasts Data-Knowledge-Action for Urban Systems explora los sistemas utilizados para construir sistemas urbanos inteligentes. La serie reflexiona sobre los cambios sistemáticos necesarios para que las ciudades se vuelvan adaptables e inteligentes para manejar el bienestar urbano. Está alojado por el Centro de Geomática Aplicada, CODATA y el Programa de Salud y Bienestar Urbano (UHWB).
Los días 15 y 16 de febrero, Simon Hodson brindó información sobre el trabajo de CODATA como parte de una sesión de intercambio de conocimientos para los miembros del ISC sobre Convergencia de ciencia y tecnología en una era digital.
Puede obtener más información sobre el proyecto WorldFAIR, sobre el trabajo de CODATA en vocabularios FAIR y sobre iniciativas en varias disciplinas de investigación para hacer que los datos y los activos de información sean FAIR en Semana Internacional de Datos 2022, 20-23 de junio.
Imagen de École polytechnique – J.Barande vía Flickr.
Artículos relacionados

Las nominaciones al Comité Científico del Sistema Mundial de Datos (WDS-SC) 2024 ya están abiertas
07.03.2024





















Datos de pérdidas por desastres en el seguimiento de la implementación del marco de Sendai
10.05.2019



Puesto vacante: Director Ejecutivo del Sistema Mundial de Datos ICSU (WDS) (anunciado nuevamente)
19.06.2018


La Oficina Internacional de Tecnología del Sistema Mundial de Datos de ICSU se abrirá en Canadá
12.04.2018

IAMAS insta a Estados Unidos a continuar apoyando los sistemas de Observación de la Tierra
04.12.2017


Belmont Forum anuncia a Mustapha Mokrane como nuevo codirector de la iniciativa de datos abiertos
06.11.2017





El Sistema Mundial de Datos marca el quinto aniversario de la Oficina de Programas Internacionales
07.04.2016
El nuevo Sistema Mundial de Datos de ICSU abre una nueva Oficina del Programa Internacional en Tokio
16.05.2012
Inaugurada la Oficina de Programas Internacionales del nuevo Sistema Mundial de Datos de ICSU
09.05.2012
Nota de asesoramiento sobre el acceso a datos compartidos para reducir la desigualdad mundial
11.01.2012
ICSU lanza una Agenda de Acción antes de la Cumbre Mundial sobre la Sociedad de la Información
17.07.2003