
The data underpinning scientific research is what fuels advances in scientific understanding. These datasets hold vital clues to many of the most pressing questions facing scientists today, and can shed new light on past findings – either validating or invalidating the existing record of science, and opening up possibilities for new research and new understanding. However, this kind of information often disappears during the process of publishing scientific findings, either because data is not shared, or not made available in a format that’s easy to access and interrogate.
‘In science, a lot of wonderful pieces of work end up published as PDF documents. Being able to print and read an article is great for humans, but a lot of information that went into constructing what’s reported in the PDF ends up hidden away. If we want to get a big-picture view, and look at all the experiments that have been done and have been reported in the literature relating to a certain process or reaction, it’s very difficult for us to extract all that information from all those PDFs,’ explains Simon Hodson, Executive Director of ISC-CODATA.
In the words of chemist Peter Murray-Rust, getting useful information out of PDFs can be like ‘reconstructing a cow from a beef burger.’
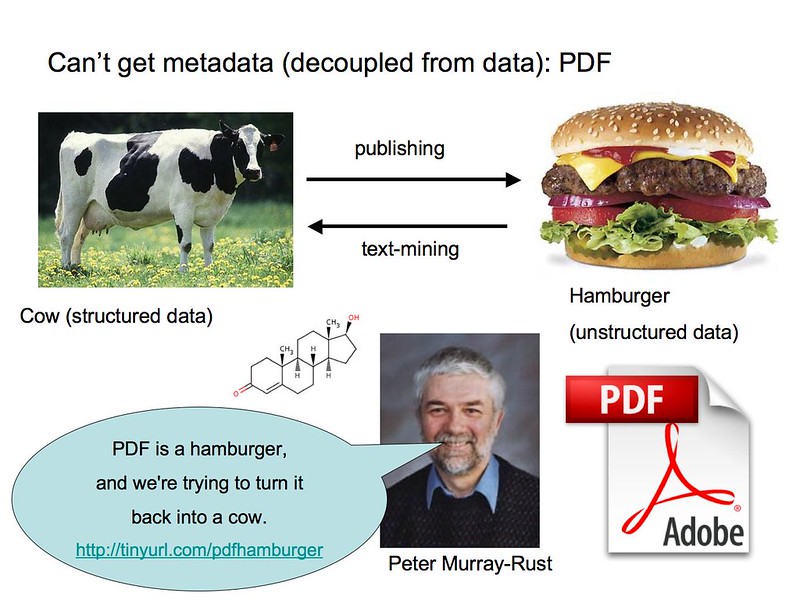
There is a wealth of scientific data that has been produced in the course of many years of research, but in many cases, it’s not possible — and certainly not easy — to find that data and query it so as to compare it with other findings or ongoing work. Faced with this conundrum, and in line with the open science imperative, researchers are currently working to further enable data-driven science through frameworks that support accessibility and interoperability of data.
One of the latest and most prominent approaches to doing this is FAIR, which encapsulates what data needs to be in order to be as usable and valuable as possible: FAIR data is data that is Findable; Accessible; Interoperable and Re-usable.
‘Findable’ means that the scientific data that is published as part of the underpinning evidence for scientific findings, or produced as the result of publicly funded research, should be available for others to find and use. Data should have a persistent and unambiguous identifier, as well as sufficiently rich metadata to enable discovery.
“There are good reasons for protecting some data,” says Simon Hodson, “but where those considerations don’t apply, the FAIR principles mean that you should be able to access the data over the web, perhaps with authorization if there are security issues. Crucially, the FAIR principles maintain that scientists should be able to access research data programmatically, that is by their machines as well. It’s not just that you can get the data and download it: you should ideally be able to query it with computer code.”
The i in FAIR refers to ‘interoperable’ – meaning that you can combine data from different sources: this largely depends on having standards for metadata and agreed terminologies or vocabularies. For example, the metadata for a social survey from a given country would clearly explain the age categories or socio-economic categories that have been used, and where the category boundaries lie, so that the data could be easily compared with data from a social survey in a different country.
R stands for reusability: this includes having a licence that allows people to reuse the data and states clearly the conditions on any reuse. It also means having information on the provenance of the data (for example, how it was gathered, what adjustments or calibrations were used, what further processing and cleaning the data has undergone etc) so that researchers can understand the potential strong points and limitations of the data, and use it with confidence.
FAIR data is also ‘Fully AI Ready’. In order to use machine learning to identify patterns and start predicting outcomes across different datasets, it’s essential to have definitions for different variables in the dataset, and the definitions have to be easily accessible.
“When data and related services are FAIR, then everything is described so that that the computer – and anyone using the code – knows what definition has been used for the concept and related variable, the way in which the measurements have been obtained, and the values themselves. Then we can interact with the data code, perhaps decomposing it, taking a subset, combining it with other data. If the data is FAIR this can be done far more efficiently and analysis and research itself benefits,” says Simon Hodson.
The idea of a having standardized vocabularies with which to express the core concepts in various realms of science is by no means new. The International Union of Pure and Applied Chemistry (IUPAC), a member of the ISC, has been responding to the need for international standardization in chemistry since its foundation in 1919. Today, it is imperative that standard vocabularies are adapted to the digital age and are themselves made FAIR. As a result of a workshop organised with the Data Documentation initiative, a group led by Simon Cox (a former member of the CODATA Executive Committee and an expert on the use of terminologies) published ‘Ten Simple Rules for Making a Vocabulary FAIR’.
Following these guidelines, CODATA is currently working on a FAIR vocabulary for the Hazard Information Profiles published by the ISC in October 2021. This will create a web-based terminology for all of the hazards described, which will be made available on GitHub and via the Research Vocabularies Australia service, for anyone to use. This means that governments developing their strategies and actions on risk reduction and management will be able to quickly compare the data with their own statistics on disaster loss or reporting frameworks, for example.
CODATA is also working on FAIR vocabularies with several different ISC Members, such as with the International Union for the Scientific Study of Population (IUSSP). Demography is a data-rich field, and is highly relevant to understanding sustainable human development. By making key terminologies in population science FAIR, IUSSP will contribute to making demographic data more useful for statistical agencies and social scientists, as well as those using such data in the many fields of study that use population data, including most areas relating to the Sustainable Development Goals (SDGs).
CODATA will also be undertaking similar work with IUPAC as part of the new two-year project ‘WorldFAIR: Global cooperation on FAIR data policy and practice’, funded by the European Commission through its Horizon Europe Framework Programme. Coordinated by CODATA, with the Research Data Alliance association as a major partner, the WorldFAIR project will work with a set of eleven domain and cross-domain case studies to advance implementation of the FAIR data principles, in particular those for Interoperability, and to develop a set of recommendations and a framework for FAIR assessment in a set of disciplines, or cross-disciplinary research areas. WorldFAIR will form the core of CODATA’s contribution to the ISC Project Making Data Work For Cross-Domain Grand Challenges.
IUPAC is leading the chemistry case study, looking at how to make the information assets and terminologies that IUPAC curates appropriate for the age of digitalization and FAIR data. IUPAC will also engage with other WorldFAIR case studies on nanomaterials and geochemistry.
Another WorldFAIR partner is Drexel University, USA, which led the Salud Urbana en América Latina (“Urban Health in Latin America”) (SALURBAL) project. SALURBAL developed a multi-country dataset on domains such as demographic characteristics, mortality rates, health behaviours and risks, the social environment and the built environment, allowing for comparisons of cities and neighbourhoods within cities across Latin America. This amazing resource will enable policy-relevant research on the drivers of health and health inequalities in the region’s cities. SALURBAL has already done extensive work on data harmonization. WorldFAIR will help shed more light on this work and will make recommendations for FAIR terminologies in urban health.

CAG-CEPT, CODATA and UHWB Podcast Series on ‘Data-Knowledge-Action for Urban Systems
The Data-Knowledge-Action for Urban Systems podcast series explores systems used to build intelligent urban systems. The series reflects on the systematic changes required for cities to become adaptive and intelligent for handling urban wellbeing. It is hosted by the Center for Applied Geomatics, CODATA, and Urban Health and Wellbeing Programme (UHWB).
On 15 and 16 February Simon Hodson gave a briefing about CODATA’s work as part of knowledge-sharing session for ISC Members on Converging Science and Technology in a Digital Era.

You can find out more about the WorldFAIR project, about CODATA’s work on FAIR vocabularies and about initiatives in various research disciplines to make data and information assets FAIR at International Data Week 2022, 20-23 June.
Image by École polytechnique – J.Barande via Flickr.
 Read more about WorldFAIR: Continuing to transform data to tackle complex challenges in a follow-up project
Read more about WorldFAIR: Continuing to transform data to tackle complex challenges in a follow-up project
 Read more about Official launch of the IDRC and ISC project to explore AI’s impact on science systems in the Global South
Read more about Official launch of the IDRC and ISC project to explore AI’s impact on science systems in the Global South
 Read more about The ISC’s Centre for Science Futures secures a million-dollar grant to explore the impacts of AI on science in the Global South
Read more about The ISC’s Centre for Science Futures secures a million-dollar grant to explore the impacts of AI on science in the Global South